設定與拆解¶
在資料工作流程中,建立資源 (例如運算資源)、使用它來執行某些工作,然後拆解它是很常見的。Airflow 提供了設定與拆解任務來支援此需求。
設定與拆解任務的主要功能
如果您清除任務,其設定與拆解也會被清除。
預設情況下,拆解任務在評估 dag 執行狀態時會被忽略。
即使工作任務失敗,如果設定成功,拆解任務仍會執行。
當針對任務群組設定依賴關係時,拆解任務會被忽略。
設定與拆解的運作方式¶
基本用法¶
假設您有一個 dag 會建立叢集、執行查詢並刪除叢集。如果不使用設定與拆解任務,您可能會設定這些關係
create_cluster >> run_query >> delete_cluster
若要將 create_cluster 和 delete_cluster 作為設定與拆解任務啟用,我們將它們標記為 as_setup 和 as_teardown 方法,並在它們之間新增上游/下游關係
create_cluster.as_setup() >> run_query >> delete_cluster.as_teardown()
create_cluster >> delete_cluster
為了方便起見,我們可以透過將 create_cluster 傳遞至 as_teardown 方法,在一行程式碼中完成此操作
create_cluster >> run_query >> delete_cluster.as_teardown(setups=create_cluster)
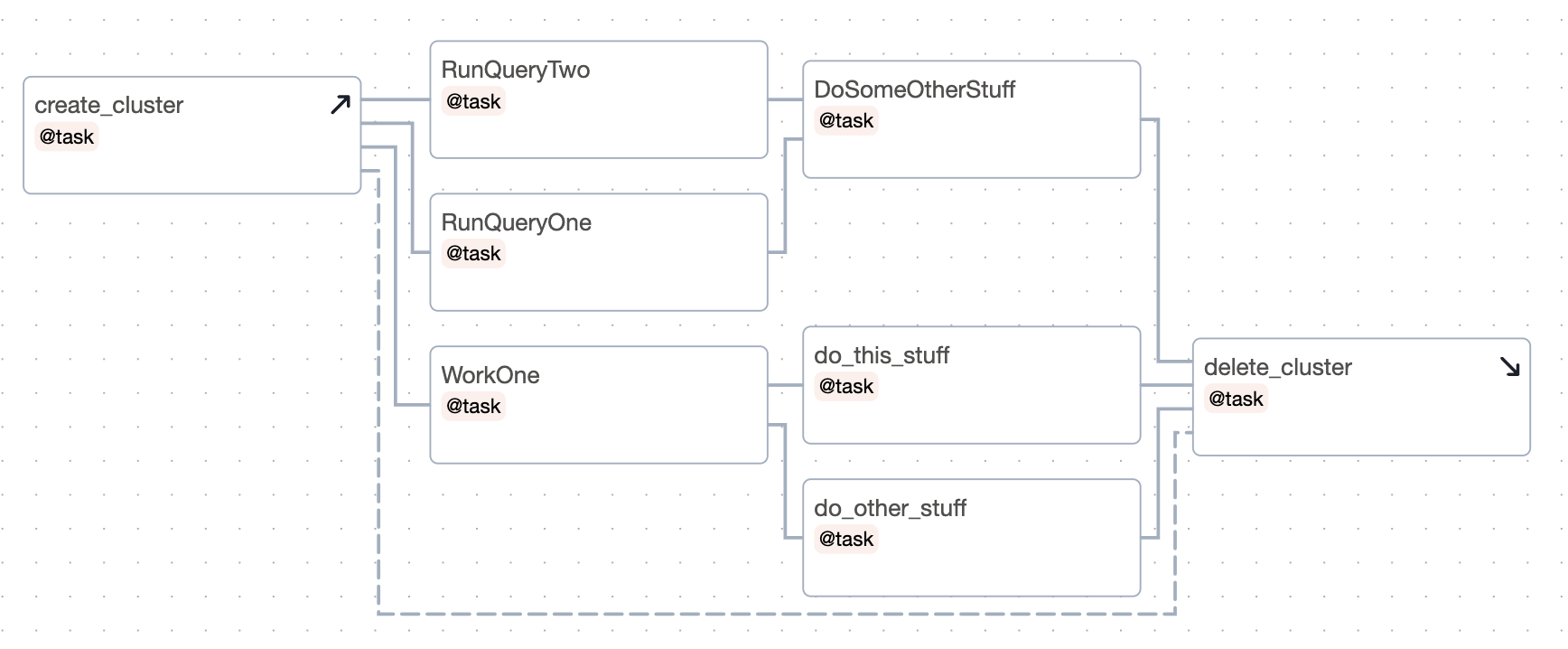
這是此 dag 的圖表

觀察
如果您清除
run_query以再次執行它,則create_cluster和delete_cluster都將被清除。如果
run_query失敗,則delete_cluster仍會執行。dag 執行的成功與否將僅取決於
run_query的成功與否。
此外,如果我們有多個任務要包裝,我們可以使用拆解作為上下文管理器
with delete_cluster().as_teardown(setups=create_cluster()):
[RunQueryOne(), RunQueryTwo()] >> DoSomeOtherStuff()
WorkOne() >> [do_this_stuff(), do_other_stuff()]
這會設定 create_cluster 在上下文中的任務之前執行,而 delete_cluster 在它們之後執行。
這是它在圖表中的顯示
請注意,如果您嘗試將已實例化的任務新增至設定上下文,則需要明確地執行此操作
with my_teardown_task as scope:
scope.add_task(work_task) # work_task was already instantiated elsewhere
設定「範圍」¶
設定及其拆解之間的任務位於設定/拆解對的「範圍」內。
讓我們來看一個例子
s1 >> w1 >> w2 >> t1.as_teardown(setups=s1) >> w3
w2 >> w4
以及圖表

在上面的範例中,w1 和 w2 位於 s1 和 t1「之間」,因此假設它們需要 s1。因此,如果清除 w1 或 w2,則 s1 和 t1 也將被清除。但是,如果清除 w3 或 w4,則 s1 和 t1 都不會被清除。
您可以將多個設定任務連接到單一拆解。如果至少一個設定成功完成,拆解將會執行。
您可以擁有沒有拆解的設定
create_cluster >> run_query >> other_task
在這種情況下,create_cluster 的所有下游都被假設為需要它。因此,如果您清除 other_task,它也會清除 create_cluster。假設我們在 run_query 之後為 create_cluster 新增一個拆解
create_cluster >> run_query >> other_task
run_query >> delete_cluster.as_teardown(setups=create_cluster)
現在,Airflow 可以推斷 other_task 不需要 create_cluster,因此如果我們清除 other_task,create_cluster 也將不會被清除。
在該範例中,我們(在我們假想的文件世界中)實際上想要刪除叢集。但是,假設我們沒有,而我們只是想說「other_task 不需要 create_cluster」,那麼我們可以使用 EmptyOperator 來限制設定的範圍
create_cluster >> run_query >> other_task
run_query >> EmptyOperator(task_id="cluster_teardown").as_teardown(setups=create_cluster)
隱含的 ALL_SUCCESS 約束¶
任何在設定範圍內的任務都對其設定具有隱含的「all_success」約束。這對於確保在清除具有間接設定的任務時,它將等待它們完成是必要的。如果設定失敗或被跳過,則依賴它們的工作任務將被標記為失敗或跳過。我們還要求直接位於設定下游的任何非拆解任務都必須具有觸發規則 ALL_SUCCESS。
控制 dag 執行狀態¶
設定/拆解任務的另一個功能是您可以選擇拆解任務是否應影響 dag 執行狀態。也許您不在乎拆解任務執行的「清理」工作是否失敗,並且您只在「工作」任務失敗時才將 dag 執行視為失敗。預設情況下,拆解任務不會被納入 dag 執行狀態的考量。
繼續上面的範例,如果您希望執行的成功與否取決於 delete_cluster,則在將 delete_cluster 設定為拆解時,設定 on_failure_fail_dagrun=True。例如
create_cluster >> run_query >> delete_cluster.as_teardown(setups=create_cluster, on_failure_fail_dagrun=True)
使用 task groups 編寫¶
當從任務群組箭頭指向任務群組,或從任務群組箭頭指向任務時,我們會忽略拆解。這允許拆解平行執行,並允許 dag 執行即使在拆解任務失敗時也能繼續進行。
考慮這個例子
with TaskGroup("my_group") as tg:
s1 = s1()
w1 = w1()
t1 = t1()
s1 >> w1 >> t1.as_teardown(setups=s1)
w2 = w2()
tg >> w2
圖表
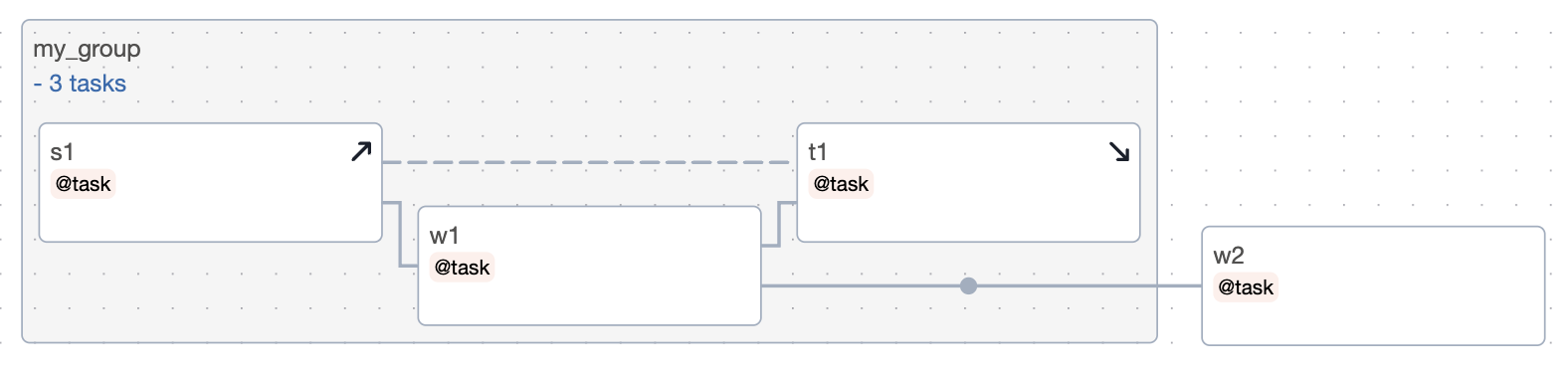
如果 t1 不是拆解任務,那麼這個 dag 實際上會是 s1 >> w1 >> t1 >> w2。但由於我們已將 t1 標記為拆解,因此在 tg >> w2 中會被忽略。因此,dag 等同於以下內容
s1 >> w1 >> [t1.as_teardown(setups=s1), w2]
現在讓我們考慮一個具有巢狀結構的範例
with TaskGroup("my_group") as tg:
s1 = s1()
w1 = w1()
t1 = t1()
s1 >> w1 >> t1.as_teardown(setups=s1)
w2 = w2()
tg >> w2
dag_s1 = dag_s1()
dag_t1 = dag_t1()
dag_s1 >> [tg, w2] >> dag_t1.as_teardown(setups=dag_s1)
圖表

在這個範例中,s1 是 dag_s1 的下游,因此它必須等待 dag_s1 成功完成。但是 t1 和 dag_t1 可以同時執行,因為 t1 在表達式 tg >> dag_t1 中被忽略。如果您清除 w2,它將清除 dag_s1 和 dag_t1,但不會清除任務群組中的任何內容。
平行執行設定與拆解¶
您可以平行執行設定任務
(
[create_cluster, create_bucket]
>> run_query
>> [delete_cluster.as_teardown(setups=create_cluster), delete_bucket.as_teardown(setups=create_bucket)]
)
圖表
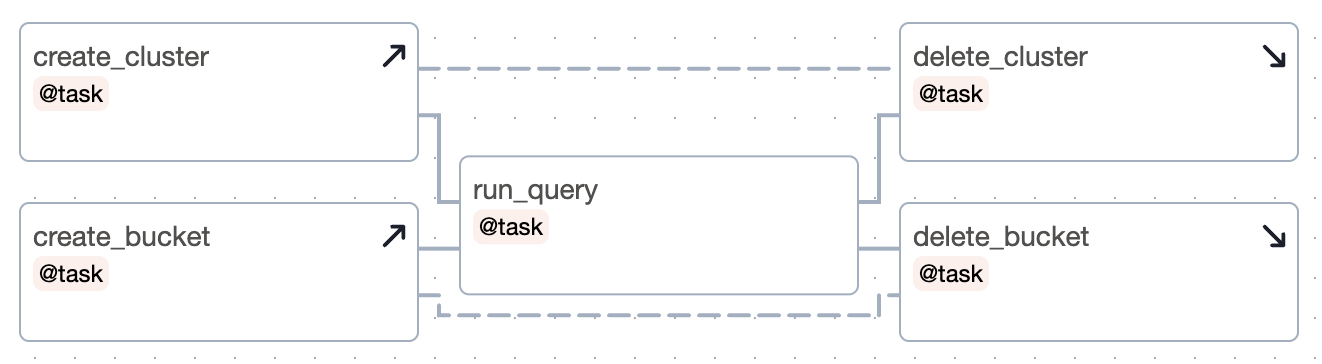
將它們放在群組中在視覺上可能會更好
with TaskGroup("setup") as tg_s:
create_cluster = create_cluster()
create_bucket = create_bucket()
run_query = run_query()
with TaskGroup("teardown") as tg_t:
delete_cluster = delete_cluster().as_teardown(setups=create_cluster)
delete_bucket = delete_bucket().as_teardown(setups=create_bucket)
tg_s >> run_query >> tg_t
以及圖表

拆解的觸發規則行為¶
拆解使用名為 ALL_DONE_SETUP_SUCCESS 的(不可配置)觸發規則。使用此規則,只要所有上游都已完成並且至少一個直接連接的設定成功,拆解就會執行。如果拆解的所有設定都被跳過或失敗,這些狀態將會傳播到拆解。