任務¶
任務是 Airflow 中執行的基本單位。任務會安排到 DAGs 中,然後在它們之間設定上游和下游的依賴關係,以便表達它們應該執行的順序。
任務有三種基本類型
操作器,預定義的任務範本,您可以快速地將它們串在一起,以建構您 DAGs 的大部分部分。
感測器,操作器的特殊子類別,完全是關於等待外部事件發生。
TaskFlow 裝飾的
@task,這是一個封裝成任務的自訂 Python 函數。
在內部,這些實際上都是 Airflow 的 BaseOperator 的子類別,任務和操作器的概念在某種程度上是可以互換的,但將它們視為獨立的概念是有用的 - 本質上,操作器和感測器是範本,當您在 DAG 檔案中呼叫一個時,您正在建立一個任務。
關聯性¶
使用任務的關鍵部分是定義它們彼此之間的關係 - 它們的依賴關係,或者在 Airflow 中我們說的,它們的上游和下游任務。您先宣告您的任務,然後再宣告它們的依賴關係。
注意
我們稱上游任務為直接在另一個任務之前的任務。我們以前稱它為父任務。請注意,這個概念並未描述任務階層中較高的任務(即,它們不是任務的直接父任務)。相同的定義適用於下游任務,它必須是另一個任務的直接子任務。
有兩種宣告依賴關係的方法 - 使用 >> 和 << (位元位移) 運算子
first_task >> second_task >> [third_task, fourth_task]
或者更明確的 set_upstream 和 set_downstream 方法
first_task.set_downstream(second_task)
third_task.set_upstream(second_task)
這兩者都做完全相同的事情,但一般來說,我們建議您使用位元位移運算子,因為在大多數情況下它們更容易閱讀。
預設情況下,任務將在其所有上游(父)任務成功完成後執行,但是有很多方法可以修改此行為以新增分支,僅等待某些上游任務,或根據目前執行在歷史記錄中的位置來變更行為。如需更多資訊,請參閱 控制流程。
任務預設不會彼此傳遞資訊,並且完全獨立執行。如果您想將資訊從一個任務傳遞到另一個任務,您應該使用 XComs。
任務實例¶
就像 DAG 在每次執行時都會被實例化為 DAG 執行 一樣,DAG 下的任務也會被實例化為任務實例。
任務的實例是該任務針對給定 DAG(因此針對給定的資料間隔)的特定執行。它們也是具有狀態的任務的表示,代表它處於生命週期的哪個階段。
任務實例的可能狀態為
none:任務尚未排隊等待執行(其依賴關係尚未滿足)scheduled:排程器已確定任務的依賴關係已滿足,並且應該執行queued:任務已分配給執行器,正在等待工作人員running:任務正在工作人員上執行(或在本地/同步執行器上)success:任務執行完成且沒有錯誤restarting:任務在執行時被外部請求重新啟動failed:任務在執行期間發生錯誤並執行失敗skipped:任務由於分支、LatestOnly 或類似原因而被略過。upstream_failed:上游任務失敗,且 觸發規則 表示我們需要它up_for_retry:任務失敗,但還有重試次數,將會重新排程。up_for_reschedule:任務是一個 感測器,處於reschedule模式deferred:任務已延遲到觸發器removed:自執行開始以來,任務已從 DAG 中消失
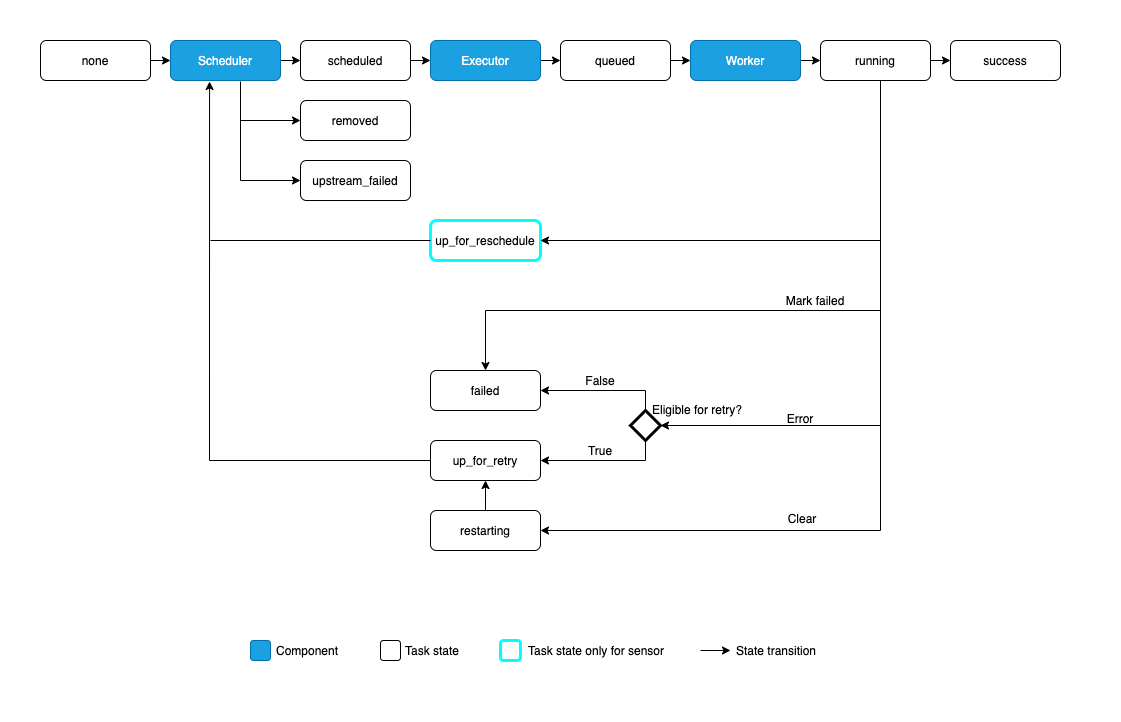
理想情況下,任務應該從 none 流向 scheduled,再到 queued,再到 running,最後到 success。
當任何自訂任務(操作器)正在執行時,它將獲得傳遞給它的任務實例的副本;除了能夠檢查任務元數據之外,它還包含諸如 XComs 等方法。
關聯性術語¶
對於任何給定的任務實例,它與其他實例有兩種關係。
首先,它可以有上游和下游任務
task1 >> task2 >> task3
當 DAG 執行時,它將為每個彼此上游/下游的任務建立實例,但這些實例都具有相同的資料間隔。
也可能存在相同任務的實例,但用於不同的資料間隔 - 來自同一個 DAG 的其他執行。我們稱它們為先前和下一個 - 它與上游和下游的關係不同!
注意
一些較舊的 Airflow 文件可能仍然使用「先前」來表示「上游」。如果您發現這種情況,請幫助我們修正它!
逾時¶
如果您希望任務具有最長執行時間,請將其 execution_timeout 屬性設定為 datetime.timedelta 值,該值為允許的最長執行時間。這適用於所有 Airflow 任務,包括感測器。execution_timeout 控制每次執行允許的最長時間。如果違反 execution_timeout,任務將逾時並引發 AirflowTaskTimeout。
此外,感測器具有 timeout 參數。這僅適用於 reschedule 模式下的感測器。timeout 控制感測器成功允許的最長時間。如果違反 timeout,將引發 AirflowSensorTimeout,並且感測器會立即失敗,而不會重試。
以下 SFTPSensor 範例說明了這一點。sensor 處於 reschedule 模式,這表示它會定期執行和重新排程,直到成功為止。
每次感測器探測 SFTP 伺服器時,都允許最多花費 60 秒,如
execution_timeout所定義。如果感測器探測 SFTP 伺服器的時間超過 60 秒,將引發
AirflowTaskTimeout。當發生這種情況時,允許感測器重試。它最多可以重試 2 次,如retries所定義。從第一次執行開始,到最終成功(即在檔案 'root/test' 出現之後),感測器允許的最長時間為 3600 秒,如
timeout所定義。換句話說,如果檔案在 3600 秒內沒有出現在 SFTP 伺服器上,感測器將引發AirflowSensorTimeout。當引發此錯誤時,它不會重試。如果感測器由於其他原因(例如在 3600 秒間隔期間發生網路中斷)而失敗,它可以重試最多 2 次,如
retries所定義。重試不會重置timeout。它仍然總共有最多 3600 秒的時間使其成功。
sensor = SFTPSensor(
task_id="sensor",
path="/root/test",
execution_timeout=timedelta(seconds=60),
timeout=3600,
retries=2,
mode="reschedule",
)
如果您只是想在任務超時時收到通知,但仍然讓它執行完成,您需要的是 SLAs。
SLAs¶
SLA 或服務等級協定,是對任務相對於 Dag 執行開始時間應完成的最長時間的期望。如果任務執行時間超過此時間,則它會在使用者介面的「SLA Misses」部分中顯示,並在電子郵件中寄出所有錯過其 SLA 的任務。
但是,超過其 SLA 的任務不會被取消 - 它們被允許執行完成。如果您想在達到特定執行時間後取消任務,您需要的是 逾時。
要為任務設定 SLA,請將 datetime.timedelta 物件傳遞給任務/操作器的 sla 參數。如果您想執行自己的邏輯,您還可以提供一個 sla_miss_callback,它將在 SLA 錯過時被呼叫。
如果您想完全停用 SLA 檢查,您可以在 Airflow 的 [core] 組態中設定 check_slas = False。
要了解更多關於配置電子郵件的資訊,請參閱 電子郵件組態。
注意
手動觸發的任務和事件驅動 DAG 中的任務將不會檢查 SLA 錯過。有關 DAG schedule 值的更多資訊,請參閱 DAG 執行。
sla_miss_callback¶
如果您想執行自己的邏輯,您還可以提供一個 sla_miss_callback,它將在 SLA 錯過時被呼叫。sla_miss_callback 的函數簽章需要 5 個參數。
dagtask_list字串清單(換行符號分隔,\n),其中包含自上次
sla_miss_callback執行以來,所有錯過其 SLA 的任務。
blocking_task_listslas與
task_list參數中的任務相關聯的SlaMiss物件的清單。
blocking_tis與
blocking_task_list參數中的任務相關聯的 TaskInstance 物件的清單。
sla_miss_callback 函數簽章的範例
def my_sla_miss_callback(dag, task_list, blocking_task_list, slas, blocking_tis):
...
def my_sla_miss_callback(*args):
...
範例 DAG
def sla_callback(dag, task_list, blocking_task_list, slas, blocking_tis):
print(
"The callback arguments are: ",
{
"dag": dag,
"task_list": task_list,
"blocking_task_list": blocking_task_list,
"slas": slas,
"blocking_tis": blocking_tis,
},
)
@dag(
schedule="*/2 * * * *",
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
sla_miss_callback=sla_callback,
default_args={"email": "email@example.com"},
)
def example_sla_dag():
@task(sla=datetime.timedelta(seconds=10))
def sleep_20():
"""Sleep for 20 seconds"""
time.sleep(20)
@task
def sleep_30():
"""Sleep for 30 seconds"""
time.sleep(30)
sleep_20() >> sleep_30()
example_dag = example_sla_dag()
特殊例外¶
如果您想從自訂任務/操作器程式碼中控制任務的狀態,Airflow 提供了兩個您可以引發的特殊例外
AirflowSkipException將目前任務標記為已略過AirflowFailException將目前任務標記為失敗忽略任何剩餘的重試次數
如果您的程式碼對其環境有額外的了解,並且想要更快地失敗/略過,這些可能會很有用 - 例如,當它知道沒有可用的資料時略過,或者當它偵測到其 API 金鑰無效時快速失敗(因為重試無法修正該問題)。
殭屍/不死任務¶
沒有系統是完美運作的,並且任務實例預期會偶爾死掉。Airflow 偵測到兩種任務/程序不符的情況
殭屍任務是
TaskInstances卡在running狀態,儘管它們關聯的作業處於非活動狀態(例如,它們的程序沒有傳送最近的心跳,因為它被終止,或者機器死機)。Airflow 將定期找到這些任務,清理它們,並根據其設定使任務失敗或重試。任務可能由於多種原因變成殭屍,包括Airflow 工作人員記憶體不足並被 OOMKilled。
Airflow 工作人員的活躍度探測失敗,因此系統(例如 Kubernetes)重新啟動了工作人員。
系統(例如 Kubernetes)縮減規模並將 Airflow 工作人員從一個節點移動到另一個節點。
不死任務是不應該執行但正在執行的任務,通常是在您透過 UI 手動編輯任務實例時造成的。Airflow 將定期找到它們並終止它們。
以下是 Airflow 排程器中的程式碼片段,該程式碼定期執行以偵測殭屍/不死任務。
def _find_and_purge_zombies(self) -> None:
"""
Find and purge zombie task instances.
Zombie instances are tasks that failed to heartbeat for too long, or
have a no-longer-running LocalTaskJob.
A TaskCallbackRequest is also created for the killed zombie to be
handled by the DAG processor, and the executor is informed to no longer
count the zombie as running when it calculates parallelism.
"""
with create_session() as session:
if zombies := self._find_zombies(session=session):
self._purge_zombies(zombies, session=session)
def _find_zombies(self, *, session: Session) -> list[tuple[TI, str, str]]:
from airflow.jobs.job import Job
self.log.debug("Finding 'running' jobs without a recent heartbeat")
limit_dttm = timezone.utcnow() - timedelta(seconds=self._zombie_threshold_secs)
zombies = (
session.execute(
select(TI, DM.fileloc, DM.processor_subdir)
.with_hint(TI, "USE INDEX (ti_state)", dialect_name="mysql")
.join(Job, TI.job_id == Job.id)
.join(DM, TI.dag_id == DM.dag_id)
.where(TI.state == TaskInstanceState.RUNNING)
.where(or_(Job.state != JobState.RUNNING, Job.latest_heartbeat < limit_dttm))
.where(Job.job_type == "LocalTaskJob")
.where(TI.queued_by_job_id == self.job.id)
)
.unique()
.all()
)
if zombies:
self.log.warning("Failing (%s) jobs without heartbeat after %s", len(zombies), limit_dttm)
return zombies
def _purge_zombies(self, zombies: list[tuple[TI, str, str]], *, session: Session) -> None:
for ti, file_loc, processor_subdir in zombies:
zombie_message_details = self._generate_zombie_message_details(ti)
request = TaskCallbackRequest(
full_filepath=file_loc,
processor_subdir=processor_subdir,
simple_task_instance=SimpleTaskInstance.from_ti(ti),
msg=str(zombie_message_details),
)
session.add(
Log(
event="heartbeat timeout",
task_instance=ti.key,
extra=(
f"Task did not emit heartbeat within time limit ({self._zombie_threshold_secs} "
"seconds) and will be terminated. "
"See https://airflow.dev.org.tw/docs/apache-airflow/"
"stable/core-concepts/tasks.html#zombie-undead-tasks"
),
)
)
self.log.error(
"Detected zombie job: %s "
"(See https://airflow.dev.org.tw/docs/apache-airflow/"
"stable/core-concepts/tasks.html#zombie-undead-tasks)",
request,
)
self.job.executor.send_callback(request)
if (executor := self._try_to_load_executor(ti.executor)) is None:
self.log.warning("Cannot clean up zombie %r with non-existent executor %s", ti, ti.executor)
continue
executor.change_state(ti.key, TaskInstanceState.FAILED, remove_running=True)
Stats.incr("zombies_killed", tags={"dag_id": ti.dag_id, "task_id": ti.task_id})
以下是上述程式碼片段中用於偵測殭屍任務的標準說明
任務實例狀態
只有處於 RUNNING 狀態的任務實例才被視為潛在的殭屍任務。
作業狀態和心跳檢查
如果關聯的作業未處於 RUNNING 狀態,或者作業的最新心跳早於計算的時間閾值 (limit_dttm),則會識別出殭屍任務。心跳是一種機制,用於指示任務或作業仍然存活並正在執行。
作業類型
與任務關聯的作業類型必須為
LocalTaskJob。由作業 ID 排隊
僅考慮由目前正在處理的相同作業排隊的任務。
這些條件共同協助根據其狀態、關聯的作業狀態、心跳狀態、作業類型以及排隊它們的特定作業來識別可能成為殭屍的執行中任務。如果任務符合這些標準,則會將其視為潛在的殭屍,並採取進一步的動作,例如記錄和傳送回呼請求。
在本機重現殭屍任務¶
如果您想為開發/測試程序重現殭屍任務,請依照以下步驟操作
為您的本地 Airflow 設定設定以下環境變數(或者,您可以調整 airflow.cfg 中的對應組態值)
export AIRFLOW__SCHEDULER__LOCAL_TASK_JOB_HEARTBEAT_SEC=600
export AIRFLOW__SCHEDULER__SCHEDULER_ZOMBIE_TASK_THRESHOLD=2
export AIRFLOW__SCHEDULER__ZOMBIE_DETECTION_INTERVAL=5
建立一個 DAG,其中包含一個需要大約 10 分鐘才能完成的任務(即長時間執行的任務)。例如,您可以使用以下 DAG
from airflow.decorators import dag
from airflow.operators.bash import BashOperator
from datetime import datetime
@dag(start_date=datetime(2021, 1, 1), schedule="@once", catchup=False)
def sleep_dag():
t1 = BashOperator(
task_id="sleep_10_minutes",
bash_command="sleep 600",
)
sleep_dag()
執行上述 DAG 並等待一段時間。您應該會看到任務實例變成殭屍任務,然後被排程器終止。